Fighting podcast spam with RSS.com

This article is at least a year old
Almost every podcast host offers a free plan - whether it’s a permanent, free account, or a starter month free.
With those free plans come a bunch of new shows. Some people try out podcasting for the first time: but some people take advantage of free plans to promote the oldest profession on the planet: the sex trade.
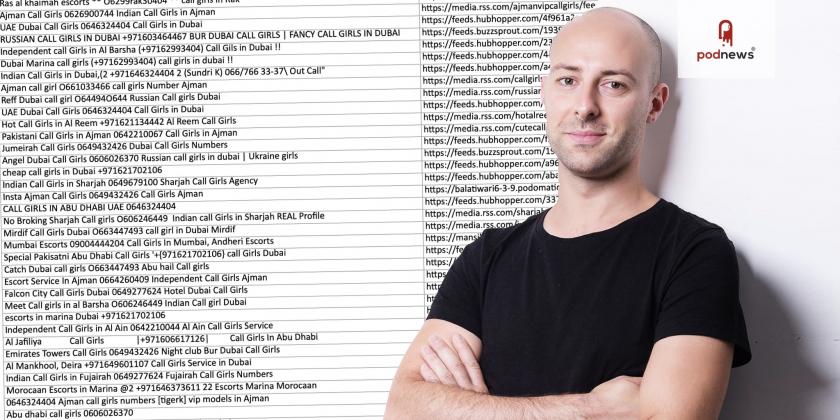
Disappointingly, sex workers aren’t suddenly producing deftly-produced audio fiction shows, true crime series, or branded content; instead, it’s as simple as using podcasting to chase SEO and better rankings in Google. (We’ve changed the telephone numbers in the above image!)
Alberto Betella from RSS.com takes up the story for Podnews:
We offer a freemium model; users can sign up and upload their first episode without a credit card. But we started to notice an increasing number of podcasts that were created only with the goal of promoting dubious and illegal services.
These podcasts were not created by bots, whose patterns are easier to automatically identify, but by real users: mainly located in India and Pakistan in our case, who manually created hundreds of shows and uploaded hundreds of fake episodes containing random noise, or random music extracts.
This behavior is harder to identify with simple rules based on IP and user agents; and we quickly realized that the goal of these spammers was twofold:
- They wanted better SEO and backlinks (the latter, via the podcast description) in the public webpage that we automatically generate for each show;
- Submission to podcast directories (including Amazon Music and Spotify among others) to appear in their search results (i.e. discoverability).
The first was simple to solve. For all the shows that only have one short episode and don’t have an active subscription to our service (i.e. those shows that are not “verified” or don’t pass our quality filters), we added the rel="ugc" attribute, and similar, to the webpage meta tags and to all the hyperlinks, following Google’s advice. This is the best deterrent for any spammer. If the webpage they create on our platform is not indexed by Google and their links are not contributing to increase any ranking, there is no point in creating these web pages.
The issue around submissions to other directories was more complex instead since spammers were submitting their spam shows, either manually or via our API integrations, to major podcast directories. If a spam podcast passes the filters of a podcast directory, then they can potentially earn visibility in search results.
On a couple of occasions, a major directory reached out to us telling us that dozens of spam podcasts we hosted were submitted to them in the short time span of a few hours. We had two options:
a. “Throw humans at the problem”, hire 1 or 2 extra people to counteract this misbehavior (perhaps also implementing a moderation queue for newly created podcasts)
b. build tech to address and mitigate the problem
We chose option B because it works at scale, it doesn’t need food and drinks, and because it’s a lot more fun! A few people in our team, in fact, have a strong AI/ML background and it doesn’t happen very often to have the opportunity to leverage this skill set in the podcasting space.
We learnt that spammers in podcasting do not rely on the episode’s audio files to be actually listened to, but they rather aim at discoverability through the appearance of titles and descriptions in search results of search engines and podcast directories.
For this reason, we focused our spam detection mainly on text and we used state-of-the-art Natural Language Processing (NLP) techniques.
First, we manually flagged the spam podcasts in our database and then we used this corpus to train our ML model, normalize the lexicon and extract relevant features such as TF-IDF, among others. Once the ML model was ready, we built an ad hoc API (aka “SpamBot”) that ingested all the new shows and all the changes in existing shows (e.g. new episodes, edited episodes), channelled them through our ML model and returned in real-time a SPAM score.
Based on this spam score our bot can:
- Flag the podcast as possible spam for human review
- Immediately auto delete the podcast if the spam score is above a certain threshold (we set it to 95%) In both cases, our podcast spambot immediately notifies our team via a slack integration. You can see in the screenshot below the latest “Dubai Call Girls” spam podcast auto deleted last week:

In the case a human review is recommended, the team can take action directly via Slack by flagging it directly as spam with the spam button.
In addition, our team can review spam podcasts and also flag false positives (if any) via our CRM, another internal tool that we built in house to control all the aspects of our product:
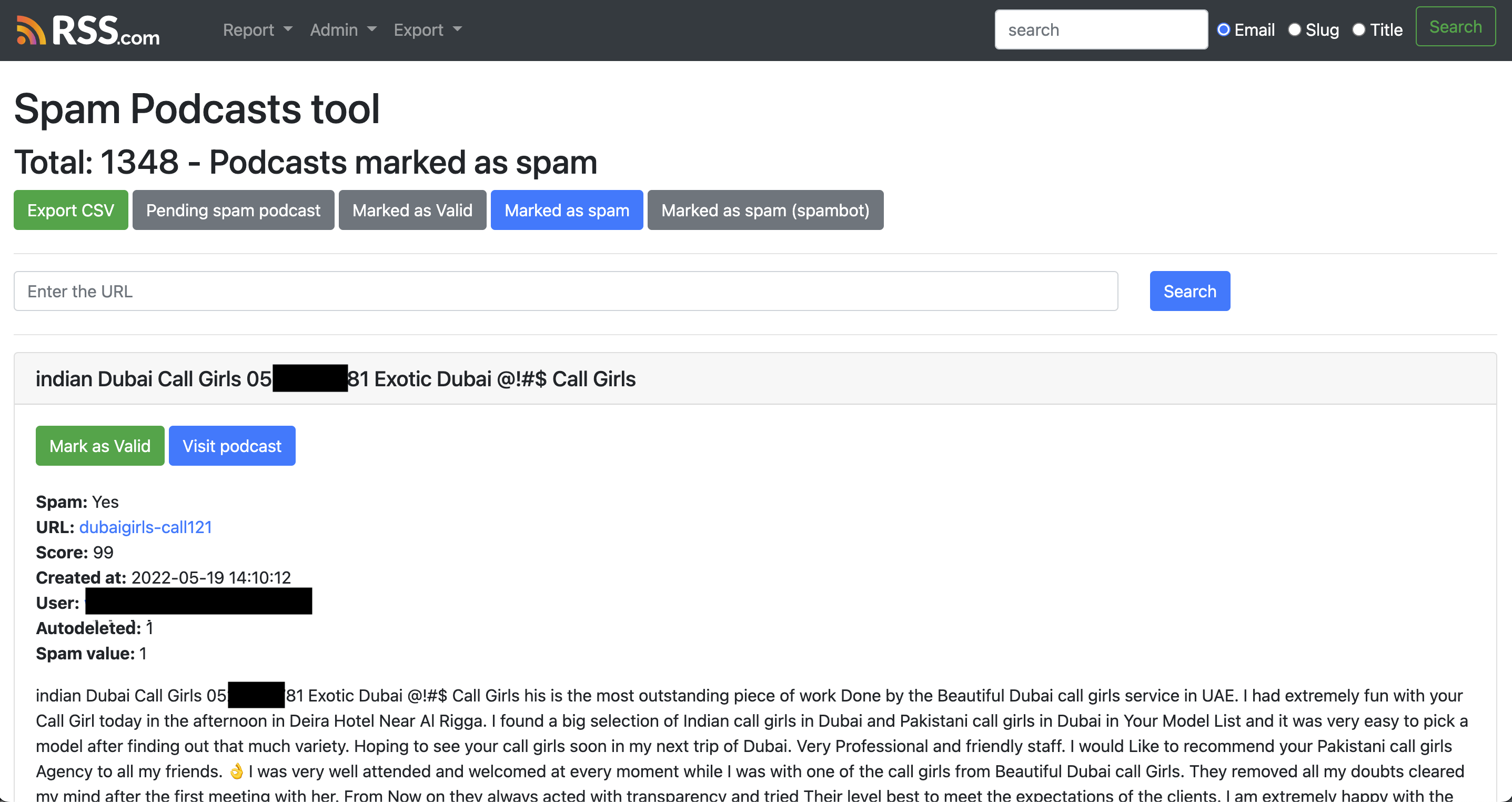
Flagging false positives via our CRM was very important at the beginning of this project to improve the accuracy of our solution.
While the accuracy of the very first spam model was not bad, over the first couple of months thanks to this semi-supervised learning approach, we were able to improve and re-train our ML model and achieve admirable results. Our model today is capable of detecting spam podcasts in a few milliseconds with high precision (99.32%, F1=.98, p < .05) as demonstrated in our confusion matrix analysis:

Effectively, our current model reduced the need for human intervention to almost zero, with very pleasing consequences for the safety of our community.
To make the model stronger, we added other parameters, including the presence of a custom cover art vs our default cover art.
Our approach is solid enough even in the case that spammers will start to use the audio files to promote spam products because audio can be transcribed into text and then fed into the same ML models we use for the description.
This is one of the reasons why in the next couple of months we’ll launch free transcripts for all RSS.com users: important for accessibility but also great for spam detection!
Fun fact: one caveat of this approach is that, because NLP models are trained using a given corpus, the languages less present in these corpora may result in false positives. This happened to us with French. Because we do not host many shows in French, it so happened that shows in French we hosted were flagged as spam (false positives) with significantly higher frequency than other languages such as English or Spanish. What we did to solve this challenge was compile a simple dataset with the top ~60 podcasts in France (title and description) and feed it as a training corpus to our ML model… et voilà! Our spambot learned French and false positives in that language were drastically reduced.
We cannot share our current ML model as open source because it is part of the unique value proposition of our company. However, we have described the methods and provided actionable recommendations for anyone that wants to build something similar. Hopefully, this is our small contribution to keep podcasting spam free!
You can get started for free with RSS.com without a credit card; but not you, suspiciously pretty-looking Russian blonde in Dubai who just wants to spend some quality private time with a new friend.