What everyone gets wrong about AI


I am probably one of the few people in this community with an actual AI research background - I have several research papers, patents (one issued, one pending), I was the head of AI for Streamyard and I’m now running my 2nd AI startup.
Considering articles like this one decrying AI slop, you might expect me to defend AI or make a rebuttal.
Here’s the thing, what I understand by the term “AI” and what most people understand by that term is very different, and my main opinion about AI is that most people don’t really understand it.
AI isn’t monolithic
People talk about AI as if it were a monolithic thing, and when I hear people blame “AI” for the flood of slop on social media, it sounds as ridiculous as blaming “math” for inflation.
What you are really complaining about are people misusing tools from companies like Midjourney, who have incorporated a specific kind of AI into their software. These companies involve AI in their software as much as the US federal reserve uses math in its forecasts.
Much like there are many kinds of math used for many different things, there are many kinds of AI used for many different things.
How they work
When people talk about AI these days, they are usually talking about AI generated images/video or Large Language Models like ChatGPT.
For most people, ChatGPT is like a helpful assistant, and you don’t need to know about the details, but sometimes the details do matter.
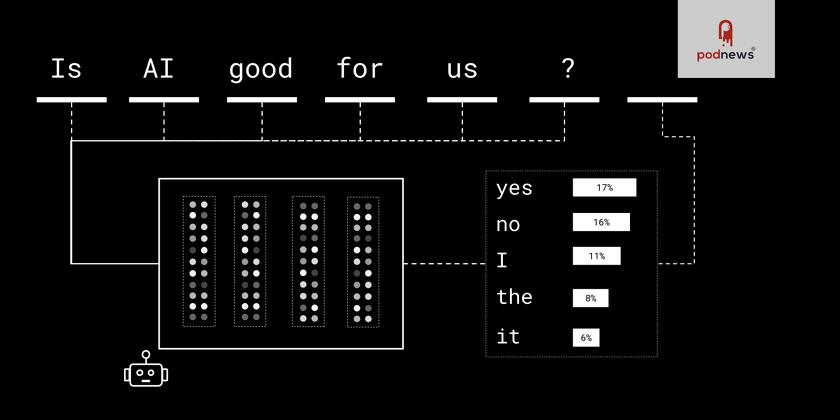
Large Language Models are so named because they are statistical models used to predict language - like the next word in a sentence. You may have heard that LLMs are basically fancy auto-complete and that’s absolutely true.
LLMs first start by taking words in a sentence, and converting each word into a list of numbers, and then do a number of math operations, and the output is a list of 50,000 numbers, one number for each word in the dictionary.
Training involves taking text, randomly hiding a portion of it, and adjusting the model weights (numbers used in the math operations) until it maximizes the number corresponding to the correct next word.
To generate a full chat response, these models start with a blank sentence, and predict the next word one word at a time. It’s as if you opened a new message on an iPhone and just kept choosing the auto-complete suggestions until you’ve written a paragraph.
The effect of this is to optimize for outputs that look like coherent sentences, even if they aren’t factually correct. Large Language Models have been trained on such large quantities of data that they actually do learn real facts, so when you write “The capital of France is ___”, these models learn to predict “Paris” as the next word.
But when an LLM “doesn’t know” something, it still predicts the next token, and will eventually make up something that sounds correct even if it isn’t - this is called “hallucination”.
You could try “The capital of armadillo is ___”. There is no word that makes sense to complete that sentence, but a standard LLM will still pick the most probable word (“the” in the case of GPT2) and it’ll go on to finish a nonsensical sentence.
If this isn’t apparent in your conversations with LLMs, it is because AI labs have hired tens of thousands of people to provide feedback to the models so that they can write good emails or working code and otherwise actually sound like a helpful human assistant.
This creates the illusion that you’re talking to someone super smart and helpful, and most people mistake this for general competence, whereas many LLMs often just make stuff up.
These AI tools are terrible
I say this because when you use AI tools like Opus Clips to find clips, all they are doing is feeding the transcript to ChatGPT and asking it to find \~30 clips, many of which just aren’t very good.
Because ChatGPT wasn’t trained on editing tasks, it will often create responses that look right on paper but are actually terrible in practice. If you ask a model to find 30 clips in a 5 minute dialog, of course it will generate nonsense.
Developers (who know as much about AI as you do) then build wrappers around these models, which are expensive and hallucinate, and everyone concludes that “well, AI isn’t perfect”
This all seems incredibly stupid and dystopian to me.
It’s not like you couldn’t build an AI system, trained by actual editors, that came up with reliably good edits. It’s entirely possible to build models that can listen to, or watch full podcast episodes, and make cuts or choose shots for artistic effect.
But that would require actual AI research and it’s a lot easier to use to build a wrapper around ChatGPT and slap “AI video editor” onto some marketing copy, so that’s what most companies in this space do.
It’s as lazy as the slop now flooding the internet, and when I read about stories like this, I don’t see an AI company, I see some idiots who hooked up to an API from Eleven Labs and are wasting everyone’s time and money.
A better way
Okay, I’ve been overly critical, so let’s talk about good uses of AI in podcasting, and I’ll focus on editing because that’s what I know best.
There are some tasks for which generative AI can do a good job like generating a podcast “intro” music or animation that might have otherwise taken days, or asking an LLM to remove a specific section of a conversation with a prompt.
At its best, AI (in the broadest sense) can either help
- Speed up the work you do
- Enable you to do things you couldn’t do before
You’re likely familiar with AI tools to remove filler or create clips but this space is still evolving and as “Agent based editing” (asking an AI model to do edits for you) gets more popular, I predict (a) you’ll see editing times go down further, and (b) people without editing experience putting out high production-value content.
AI coding tools have made it possible for small teams or even individual programmers to do what previously only large companies could do, and I suspect that in the world of podcasting, talented individual creators will now be making content at a level of production quality that would have previously required a full team.
While many AI editing tools aren’t great right now, market dynamics dictate they will either improve or perish, and I’m certainly improving mine.
Despite the rise of video podcasting, I know a lot of audio podcasters have been hesitant to go into video. The primary hesitation I hear though is around the added complexity of video editing, but, as editing gets easier I’d guess you’d see more podcasters going into video. In the past, creating a separate audio edit that respects audio as a medium, and a separate video edit that takes advantage of video as a medium, would have been too much editing effort, but if automation can reduce editing effort, I don’t see why more podcasts wouldn’t be able to embrace multiple formats.
With AI to help you edit, it doesn’t have to be “Audio” or “Video” - it can be “Yes and”?








































































